教程详情
文件下载 | 文件名称:廖雪峰商业爬虫 | 文件大小:36.2GB |
| 下载声明:本站文件大多来自于网络,仅供学习和研究使用,不得用于商业用途,如有版权问题,请联系博猪! | ||
| 下载地址: 下载教程 | ||
1.http:(1)当⽤户在地址输⼊了⽹址 发送⽹络请求的过程是什么
(2)http的请求⽅式
get请求
(1)⽐较便捷
缺点:不安全:明⽂
参数的⻓度有限制
post请求
(1)⽐较安全
(2)数据整体没有限制
(3)上传⽂件
put(不完全的)
delete(删除⼀些信息)
head(请求头)
发送⽹络请求(需要带⼀定的数据给服务器不带数据也可以)
请求头⾥⾯requestheader
返回数据:response
(1)Accept:⽂本的格式
(2)Accept-Encoding:编码格式
(3)Connection:⻓链接 短链接
(4)Cookie:验证⽤的
(5)Host:域名
(6)Referer:标志从哪个⻚⾯跳转过来的
(7)User-Agent:浏览器和⽤户的信息
2.爬⾍⼊⻔:使⽤代码模拟⽤户 批量的发送⽹络请求 批量的获取数据
(1)爬⾍的价值:
1.买卖数据(⾼端的领域价格特别贵)
2.数据分析:出分析报告
3.流量
4.指数阿⾥指数,百度指数
(3)合法性:灰⾊产业
政府没有法律规定爬⾍是违法的,也没有法律规定爬⾍是合法的
公司概念:公司让你爬数据库(窃取商业机密)责任在公司
(4)爬⾍可以爬取所有东⻄?(不是)爬⾍只能爬取⽤户能访问到的数据
爱奇艺的视频(vip⾮vip)
1.普通⽤户 只能看⾮vip 爬取⾮vip的的视频
2.vip 爬取vip的视频
3.普通⽤户想要爬取vip视频(⿊客)
爬⾍的分类:(1)通⽤爬⾍
1.使⽤搜索引擎:百度 ⾕歌 360 雅⻁ 搜狗
优势:开放性 速度快
劣势:⽬标不明确
返回内容:基本上%90是⽤户不需要的
不清楚⽤户的需求在哪⾥
(2)聚焦爬⾍(学习)
1.⽬标明确
2.对⽤户的需求⾮常精准
3.返回的内容很固定
增量式:翻⻚:从第⼀⻚请求到最后⼀⻚
Deep 深度爬⾍:静态数据:html css
动态数据:js代码,加密的js
robots:是否允许其他爬⾍(通⽤爬⾍)爬取某些内容
聚焦爬⾍不遵守robots
爬⾍和反扒做⽃争:资源对等 胜利的永远是爬⾍
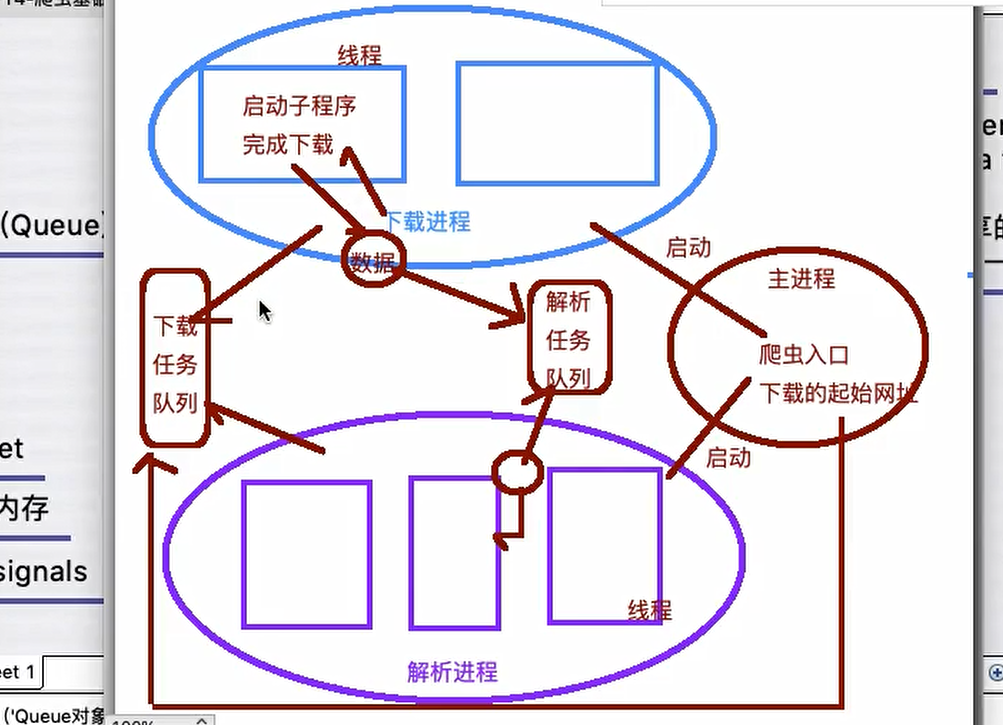
爬⾍的⼯作原理:
1.缺⼈你抓取⽬标的url是哪⼀个(找)
2.使⽤python代码发送请求获取数据(java Go)
3.解析获取到的数据(精确数据)
(1)找到新的⽬标(url)回到第⼀步(⾃动化)
4.数据持久化
python3(原⽣提供的模块):urlib.rquest:
(1)urlopen :
1.返回response对象
2.response.read()
3.bytes.decode("utf-8")
(2)get:传参
1.汉字报错 :解释器ascii没有汉字,url汉字转码
(3)post
(4)handle处理器的⾃定义
(5)urlError
python(原⽣提供的):urlib2
接下来将的知识点:
5.request(第三⽅)
6.数据解析:xpath bs4
7.数据存储
教程截图
教程下载
原文链接:【教程宝盒网】 https://www.jc-box.com/3408.html,转载请注明出处。





请先 !